
Where I work, we currently use a third party SSO provider to access most of the day-to-day applications we use. When I went this morning to log my hours for the week, I got a Server 500 error!
Unfortunately, the cloud SSO provider was offline.

This, it turns out, was due to an AWS failure in US-East-1. I’m sure there’s going to be some good post-mortems with lessons leaned blog posts coming out of a failure of this type, so I’m not going to get into that, other than to say that I think Okta can take down their 100% uptime claim.
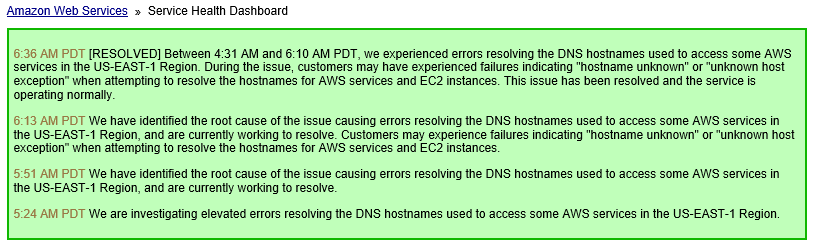
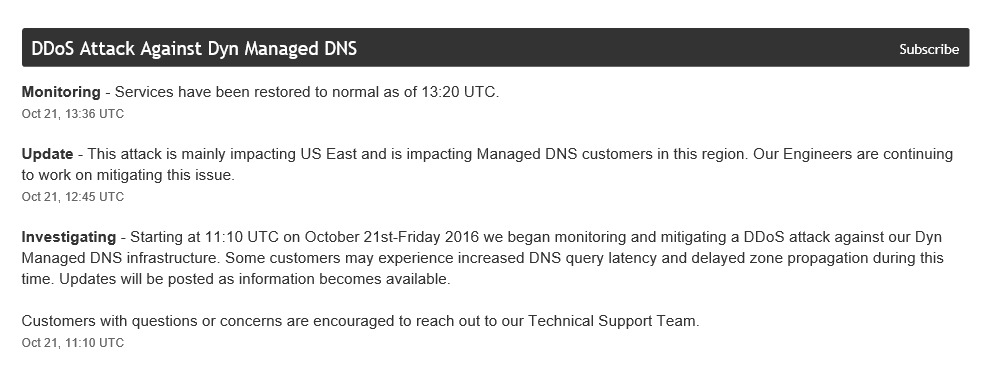
It’s not just our SSO provider that was down this morning though. It was a lot of people, including Twitter, GitHub, Spotify, and – critically for some people – PagerDuty. Interesting to note that certain adult entertainment sites didn’t go down. Right now, I’m unclear whether they’re related or not, but reports are saying that these sites were impacted by a massive DDoS attack against Dyn
This serves to reinforce the fact that systems fail. The third-party SSO provider has excellent architecture, but it still failed. DNS is moderately difficult to design around – you can have DNS provide intelligent load balancing (like Traffic Manager does) to handle outages, but you’re still relying on Traffic Manager to provide that service. Furthermore, because you’re relying on extremely short TTL, you can quickly run into caching problems. Whether you use GoDaddy, EasyDNS, Azure DNS, or self-host, these things can happen – having a second or third DNS provider is just good sense.
What is critical is having a contingency plan around failure. In this scenario, having excellent monitoring of the critical DNS service – not just the application – would allow the operations team to start the process of moving services to a provider with working DNS. Hopefully, this is a possibility. I’m not an AWS expert – from what I infer from the above service outage, the DNS services that resolve AWS instances were offline, which is similar to the cloudapp.net domain in Azure. This is difficult to work around, without having services available in another cloud. Many applications can cache content at various levels of the application, but, in this case, it would be a horrible security issue if logon tokens were cached and allowed to be used without actually being validated.
Update: 2016-10-24 – Apparently, Amazon was relying on Dyn to resolve all of the US-East-1 instances. That’s a huge no-no – and they even knew better, because other regions were available. So, I’m not sure what gives. Also, make sure you have secondary nameservers. This whole thing could have been avoided had multiple providers been available.
We can learn from Professional Engineering’s experiences here, and apply their solutions to applications in the cloud – model threats, apply risk scores, and enable the business to make an intelligent decision. If the failure of a single component will cause the entire application to fail, it’s probably worth investing more effort to design workarounds for potential failures. If the failure of a single component causes only a portion of the application to fail, it may be less worthwhile to put effort into reducing failure.

One of the talks at Ignite that I attended discussed this, and it’s worthwhile reviewing for high-level principles of infrastructure and application design for failure. You can find it here: Developing an Application Availability “Threat Model”
Related to this – ChaosMonkey 2.0 is out[footnote]Read more about the Principles of Chaos Engineering. [/footnote]. There’s some removed features that may be valuable to you – it just kills instances now, rather than being able to chew up resources (CPU, disk, RAM, etc). You may find that previous versions are what you really need. Incidentally, the Netflix Tech Blog is always worth reading to learn more about application resiliency. Chances are, a problem quite similar to yours has already been solved – designing for failure has been around for a long, long time in computer-years.